Neuron7's AI Accuracy: New NLP Models for
Reducing Noise in Extracted Knowledge

Neuron7 uses artificial intelligence (AI) to help customer service organizations resolve issues faster by extracting and understanding data from unstructured sources like service tickets and knowledge base articles.
Service tickets contain most of a support organization’s knowledge including problem descriptions and how issues were diagnosed and solved. But this textual data is challenging to work with, even for large AI models, because it often includes domain-specific verbiage and irrelevant information that make it difficult to extract valuable insights.
For example, a general-purpose AI will look at a service request where the technician wrote that “the customer is not available” and extract “customer not available” as an issue. However, this issue is not tied to a specific resolution, and results in flooding the users with irrelevant and nonsense information when they look for the right resolution.
At Neuron7, we have developed a set of natural language processing (NLP) models specifically designed to address these challenges. One key aspect of these models is our proprietary data sets, which we have carefully constructed to help train the models to better identify what information is relevant in the domain of service tickets. This data set has been essential in enabling our models to more accurately understand the context and intent behind each piece of text.
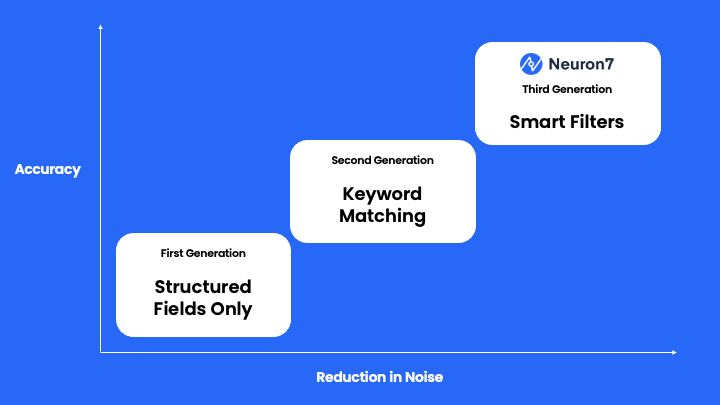
In addition to our proprietary data set, we have also incorporated the latest transformer algorithm, CoID Fusion, into our NLP models. CoID Fusion is a variant of the RoBERTa model developed by IBM, and it is based on a collaborative approach to model development. This model is trained on multiple data sets, similar to the way GPT3.5 models (like ChatGPT) are trained on user tasks. RoBERTa, or the “RoBERTa: A Robustly Optimized BERT Pretraining Approach” model, is a state-of-the-art NLP model developed by Facebook AI. It builds on the success of the BERT model (which stands for “Bidirectional Encoder Representations from Transformers”) by further improving the training process and increasing the size of the model. This allows RoBERTa to better understand the nuances and complexities of language, resulting in more accurate and reliable extracted data.
By combining our proprietary data set with the power of the CoID Fusion RoBERTa algorithm, our NLP models are able to effectively sift through large amounts of unstructured data and extract only the most relevant and useful information. This enables companies to more easily make sense of their service tickets and knowledge base articles and turn them into actionable insights.
If you’re interested in learning more about how Neuron7’s NLP models can help your business make sense of unstructured data, feel free to reach out to us. We’d be happy to answer any questions you may have about our technology.
Contact Us
Resolve issues faster with AI that understands your service data and continually learns as you use it.