Search 2.0: The Role of LLMs in Intelligent Search
by Amit Verma, Head of Engineering
In the rapidly evolving landscape of information retrieval, Search 2.0 is ushering in a new era of efficiency and precision. At the heart of this transformation lies the seamless integration of Large Language Models (LLMs), redefining how queries are processed, optimized, and ultimately generating responses.
Let’s delve into the emerging architecture that is shaping the future of search and let’s dive deeper into each of these building blocks to understand them in a bit more detail.
LLMs in Query Optimization
The foundation of Search 2.0 is laid with the utilization of advanced LLMs in query optimization. These models, such as GPT-4, Mistral, Llama 2, and others have demonstrated unparalleled capabilities in understanding context, intent, and nuances within natural language. By harnessing the power of RLHF, zero-shot (ZSL), and few-shot learning (FSL), LLMs adapt to user queries with unprecedented flexibility allowing systems to react to long-tail queries, emerging concepts, as well as personalized queries.

Embedding Optimized Queries
Once the user query undergoes optimization through LLMs, the next step involves embedding the optimized query. This is a pivotal stage where the refined query, enriched with contextual understanding, is transformed into a vector representation. This embedding process ensures that the query is encoded into a format that facilitates efficient and accurate comparison with the underlying data. Not all text embedding models are the same. Some models are better at capturing the meaning of individual words, while others are better at capturing the relationships between words. Universal Sentence Encoder, Sentence-BERT, and OpenAI are just a few of the many options available and they differ in architecture, training data, and task specificity amongst others.
Querying Vector Database
In Search 2.0, traditional keyword-based querying takes a back seat. Instead, the optimized query in vector format is employed to query a Vector Database. This database is designed to store vector representations of documents or data points, allowing for similarity searches. The result is a more nuanced and context-aware retrieval of information, aligning closely with the user’s intent. Just like embedding models, there are choices available for vector databases such as Pinecone, Chroma, and Elasticsearch amongst others, and performance, scalability, feature richness and cost would be some key considerations to make informed choices.
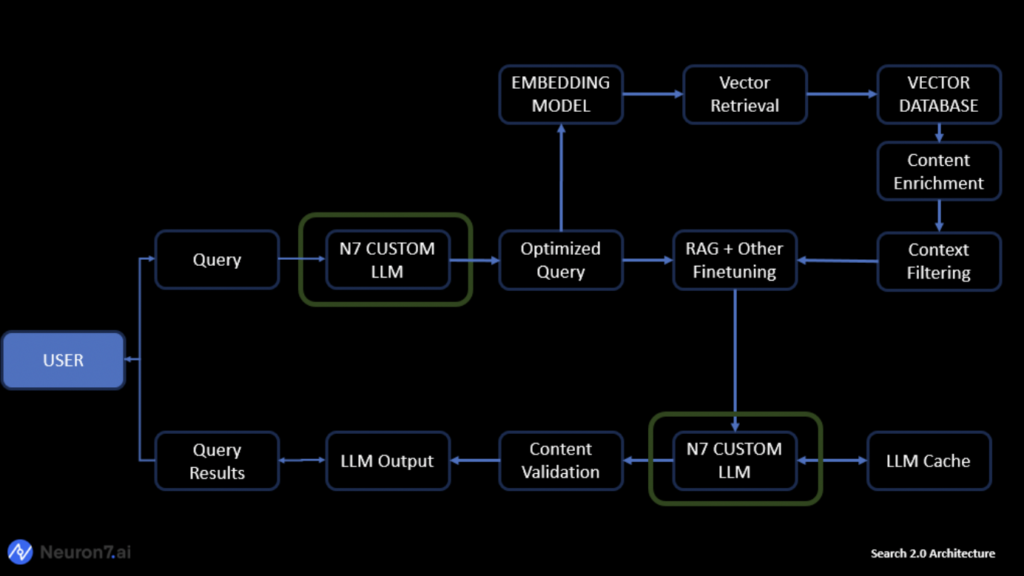
RAG and LLM Optimizations for Gen AI Response
With the retrieved vectors, the final piece of the puzzle falls into place using Retrieval-Augmented Generation (RAG) or other LLM optimizations. The contextually rich vectors, combined with generative capabilities, allow for the creation of highly tailored responses. RAG enhances the response generation process by integrating information retrieved from external knowledge bases. RAG thus has two sources of knowledge: the knowledge that the models store in their parameters (parametric memory) and the knowledge stored in the corpus from which RAG retrieves passages (nonparametric memory). This ensures that the generated response is not only contextually accurate but also informed by a broader understanding of the topic.
The Synergy of Components
The seamless synergy of these components in which LLMs optimize user queries, embeddings ensure efficient representation, vector databases facilitate context-aware searches, and RAG or other LLM optimizations bring the generated response to life. This holistic approach minimizes the gap between user intent and search results, offering an unparalleled user experience in information retrieval.
“It’s crucial to avoid viewing LLMs as a magic wand capable of solving all search problems”
LLMs Won’t Solve it All
While LLMs offer a wealth of potential for search applications, it’s crucial to avoid viewing them as a magic wand capable of solving all search problems or generating perfect outputs. LLMs are trained on massive datasets of text and code, but this information remains primarily in statistical patterns. The quality and accuracy of an LLM’s output largely depend on the quality and diversity of the data it was trained on.
Search is not a solved problem as customers’ queries can be ambiguously worded, complex/multi-step, or require knowledge that the model can’t parse. With enough fine-tuning, LLMs can be trained to address these shortcomings, but they may need to be trained on thousands of questions that can and can’t be answered, and unfortunately, that information may be ever-changing.
RAG helps in ingesting context about the latest and most accurate information, but RAG isn’t perfect either, and is tightly coupled with the quality of retrieved information which depends heavily on the quality of the external knowledge sources it is connected to, as well as the information retrieval techniques.
LLMs represent a significant leap forward in the field of artificial intelligence, but they are not a magic solution. At Neuron7, we are focused on innovating at both ends of the process: retrieval, how to find and fetch the most relevant information possible to feed the LLM; and generation, how to best structure that information to get the richest responses from the LLM. Contact us at info@neuron7.ai to learn more.